Orbis
From Signals to Understanding; Building the AI Personalization Layer
How a memory architecture reduced time-to-insight from 6–8 hours to under 15 seconds.
Relevant to: agentic surfaces, personalization, recommendations, ranking, user intent, AI evaluation, shared ML infrastructure.
Context
Product Type
AI personalization and memory layer
Team
23 across data science / ML, product, engineering, design and QA
Scope
Defined the shared reasoning-layer approach and operating model so multiple applications could reuse memory, context, and personalization capabilities.
Role
Senior Manager, Product & Engineering: led product strategy, roadmap direction, cross-functional execution, and alignment across product, data science, engineering, design and QA.
The Bridge: From Enterprise Signals to Consumer Discovery
Orbis was built in an enterprise AI environment, but the product pattern is the same one behind strong consumer discovery systems: understand user intent, remember context, rank what matters next, and adapt as behavior changes. The same architecture applies to content discovery, recommendations, ranking, assistive browsing, and agentic surfaces where the product has to decide what to surface, when, and why.
The Real Problem
What we initially believed:
The path forward was smarter individual products, better models, richer signals per tool. More model capability meant better outputs.
What we realized:
We didn't have a model problem. We had an infrastructure problem. Without shared memory, every product was stateless. Every user was a stranger to the system every single session.
Users could see individual signal, but they couldn’t:
Pick up where they left off, every session started from zero
Get context on why something mattered now versus before
Trust the system to surface what was relevant without going to find it themselves
The risk wasn’t underpowered products. The risk was overwhelming users with intelligence they couldn’t synthesize.
The Moment: Personalization isn't a feature. It's a foundation. When you give a system memory, context, and the ability to connect what it knows, it stops being a tool and starts being a thinking partner.
The Strategic Tradeoff
We faced a foundational decision:
Option A:
Continue embedding intelligence separately inside each product
Faster short-term wins
Increasing fragmentation over time
…
Option B:
Invest in a shared reasoning layer above all products
Slower initial delivery
Clear path to coherence, reuse, and scale
We chose Option B, invest in a shared reasoning layer above all products
The pushback was not about vision, but readiness.
Data Science wanted to build foundational models. I thought we needed to build AI infrastructure. I didn't win that argument with a slide deck, I pulled two engineers and built a prototype on our actual data. When we could show the system connecting signals, tracking change over time, and surfacing what mattered next, the room changed. After that I restructured the teams into pods: memory architecture, guardrails and security, data orchestration, application layer. 60+ people moving in parallel without stepping on each other.
We codified a platform standard:
Personalization is a shared capability, not a local feature…
Once this decision was made, local intelligence implementations were deprecated by design
This became a structural requirement, ensuring coherence at scale.
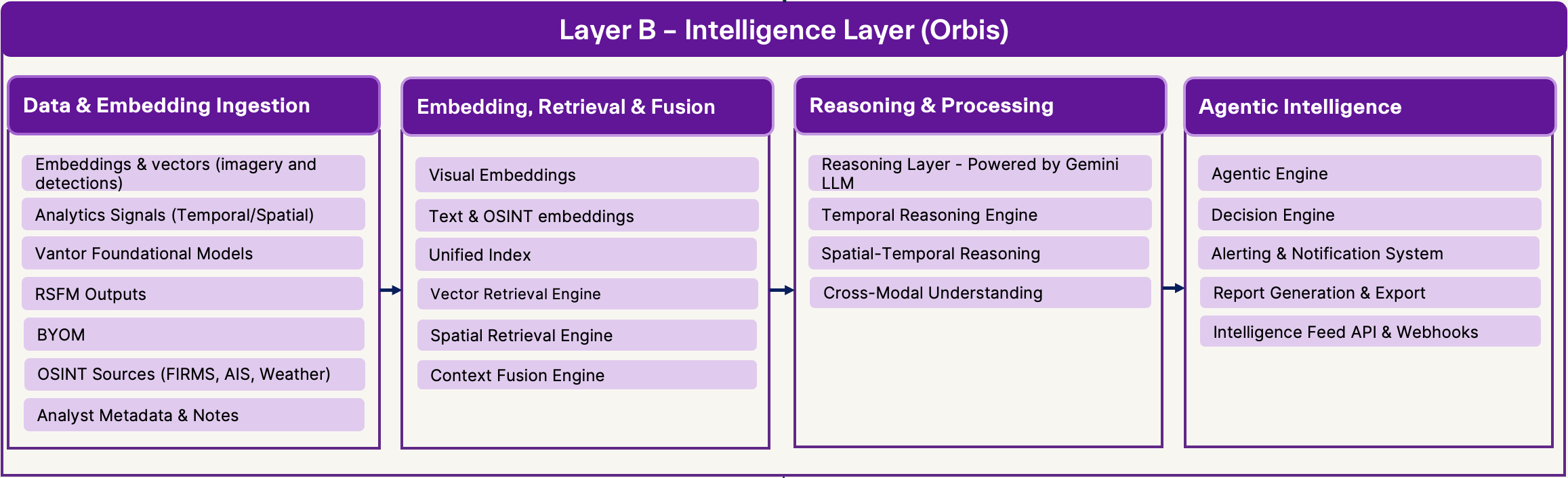
Orbis unified memory, context, and reasoning across products instead of duplicating intelligence inside each one.
What that meant in practice:
We prioritized:
Shared memory layer: episodic context, knowledge graph, vector retrieval, one foundation all products inherit
Personalized surfacing: alerts, recommendations, and summaries routed to the right user at the right time
User annotations as signal: when a user flagged something, that judgment became part of the system
We deferred:
Polished UI surfaces: the memory worked before users could see it working
Per-product model optimization: foundation first, features second
The goal was not solving insight problems one product at a time and instead designed a foundation that could unify memory, context, and interpretation across the platform. The short-term cost was speed; the long-term gain was coherence.
The Quality Bar
We evaluated Orbis against one question: did the system make users faster, clearer, and more confident than the manual workflow it replaced?
Speed
Could users move from raw signal to usable insight faster than before?
Relevance
Did the system surface what actually mattered, or just more information?
Adaptation
Did user corrections, annotations, and changing context improve future outputs?
Trust
Could users understand why something was surfaced and decide what to do next?
Outcome
This decision set a precedent for how platform bets are evaluated, and would have been the failure point had coherence not emerged.
Impact:
6–8 hours → under 15 seconds time-to-insight
60+ person org restructured around platform architecture
$300M pipeline - Orbis was a core differentiator in deals
Multiple products shipped personalization without rebuilding memory logic
Org strategy shifted from model-first to infrastructure-first permanently
What I’d Do Differently
I would have instrumented personalization quality earlier: whether surfaced insights were accepted, ignored, corrected, reused, or became part of a user’s next workflow.
Orbis defines how I think about AI personalization. Site Sentry shows how that thinking shipped under real-world constraints.